Genetic research and modern drug discovery techniques create masses of data for researchers to trawl through to find that all important scientific breakthrough. Qlucore is helping scientists see those potential ‘eureka’ moments more clearly.
With such vast amounts of data to consider, it can be difficult for scientists to understand the true biological meaning of their research. However, new data visualisation techniques are now making it much easier to uncover new and unexpected results.
As recently as 10 years ago, many biologists were still working with glass slides that revealed a few thousand features of the genes that they were studying, but that number has grown dramatically in recent years, thanks to advances in technology. As such, it has become much more difficult for biologists to identify which genes are being expressed, and to what level.
With such a large volume of data to consider, it is often impossible for these scientists to derive any real biological meaning from their findings with the naked eye alone, which means that sophisticated data algorithms need to be developed to interpret this data effectively. As a result, much of the computer software that has been designed for use in this area has focused on being able to handle increasingly vast amounts of data.
Unfortunately, this shift in focus has (unintentionally) pushed scientists and researchers to one side, since a lot of data analysis must now be performed by specialist bioinformaticians and biostatisticians, especially when complicated algorithms are required for the analysis. This model has several drawbacks, however, since it is typically the scientist who knows the most about the specific subject area being studied.
The good news for scientists is that the latest data visualisation techniques and imaging technologies are already making it much easier for the researchers themselves to examine this enormous quantity of data, to test different hypotheses and to explore alternative scenarios within seconds, since important findings can now be displayed in an easy-to-interpret graphical form.
gene expression profiling
During the past decade, research into molecular biology has helped to identify a large number of disease-associated genes and is therefore helping researchers to unpick the fundamental biology of major illnesses. Gene expression profiling, for example, is now regularly being used for the study of many serious diseases.
Gene expression experiments help to measure the activity (the expression) of tens of thousands of genes at once, creating a global picture of cellular function. These findings can then be used to distinguish between cells that are actively dividing, for example, or to show how the cells react to a particular treatment. As part of this process, researchers often must consider sub-groups (such as patients who are in remission versus patients who have suffered a relapse), while also examining the different types of cell abnormalities related to clinical conditions such as diabetes and cancer.
Difficulties can arise, however, as a result of the vast volume of data that is created by experiments like these. This ‘data overload’ can present a serious problem for researchers, since it is essential to capture, explore and analyse this kind of data effectively to obtain the most meaningful results.
To address this issue, a new generation of data visualisation tools has been designed to take full advantage of the most powerful pattern recogniser that exists: the human brain. Indeed, powerful software engines are already being used to help researchers to visualise their data in 3D, so that they can identify hidden structures and patterns more easily, and therefore identify any interesting or significant results easily, by themselves, without having to rely on specialist bioinformaticians and biostatisticians.
Data visualisation enables patterns to be visualised by projecting high dimensional data down to lower dimensions, which can then be plotted in 3D on a computer screen, and then rotated manually or automatically and examined by the naked eye.
With the benefit of instant user feedback on all of these actions, scientists studying diseases such as diabetes and leukaemia can now easily analyse their findings in real-time, directly on their computer screen and in an easy-to-interpret graphical form.
Scientists are already making use of this exciting new technology in a real-world setting. For example, a large EU-funded research project is attempting to develop and optimise in vitro test strategies that could reduce or replace animal testing for sensitisation studies.
The project, known as Sens-it-iv, combines both private and public research institutions, as well as several industrial and societal interest organisations. Dr Ann-Sofie Albrekt is currently using advanced data analysis software for her work in this important area, under the supervision of Professor Carl Borrebaeck, a sub-coordinator of Sens-it-iv.
‘In our studies, we are dealing with very large amounts of data, sometimes between 10 and 100 million data points, which we tend to view as graphics. With earlier applications, these graphics would take a long time to appear, but with the latest data analysis tools these 3D images are presented instantly,’ says Dr Albrekt. ‘As a result, we can be much more creative with our theories, as we can easily test any number of hypotheses in rapid succession and see the results at a glance.’
When used during research in this way, the ability to visualise data in 3D represents a very powerful tool for scientists, since the human brain is very good at detecting structures and patterns. The idea behind this approach is that highly complex data will be easier to comprehend by giving it a graphic form. As such, this approach to information visualisation offers a way to transform raw data into a comprehensible graphical format, so that scientists can make decisions based on information that they can identify and understand easily.
heat maps and PCA
New imaging functions contained within the latest data analysis applications are currently allowing scientists to analyse very large data sets by using a combination of different visualisation techniques, such as Heatmaps and Principal Component Analysis (PCA). With visualisation tools like these, it is possible to investigate large and complex data sets without being a statistics expert, since visualising information reduces the time required to take in data, make sense of it and draw conclusions from it.
The process begins by reducing high dimension data down to lower dimensions so that it can be plotted in 3D. PCA is often used for this purpose, as it employs a mathematical procedure to transform a number of possibly correlated variables into a number of uncorrelated variables (called principal components).
One of the key breakthroughs in the latest generation of bioinformatics software is the introduction of dynamic PCA, an innovative way of combining PCA with immediate user interaction. This feature allows scientists to manipulate different PCA-plots – interactively and in real time – directly on the computer screen and, at the same time, work with all annotations and other links in a fully integrated way. With this approach, researchers are given the freedom to explore all possible versions of the presented view and to visualise, analyse and explore a large dataset easily.
By using a tool known as a ‘heat map’ alongside dynamic PCA, scientists have yet another way of visualising their data, since heat maps can take the values of a variable in a two-dimensional map and represent them as different colours. Because modern heat maps use sophisticated mapping techniques to represent this data (as opposed to standard charting and graphing techniques), they can provide a view of data that is simply not possible to achieve with simple charts and graphs.
Also, because they are often obtained from DNA microarrays, biology heat maps are often used to represent the level of expression of many genes across a number of comparable samples, such as cells in different states or samples from different patients. Heat maps are also popular for their ability to be dynamically updated when any filter parameters are changed.
A group of scientists studying the human eye at the Division of Ophthalmology and Visual Sciences at Queen’s Medical Centre (QMC), part of the University of Nottingham, regularly use heat maps as part of their study of the Limbal stem cells on the ocular surface of the eye.
‘Compared with what is possible with modern data analysis software, previous studies were more complex to analyse and difficult for biologists to understand,’ says Dr Bina Kulkarni, one of the researchers working at QMC. ‘Data analysis is now much easier, as the latest software in this area provides instant graphical visualisation of the statistical tests in the form of heat maps, as well as variable and sample PCA plots, which really helps us to understand the analysis and the changes in gene expression patterns across different samples.’
future developments
As computer technology improves – with greater processing power, better graphics applications and more sophisticated analysis software – data visualisation will continue to develop as well. As such, these new methods of visualising data are likely to make traditional forms of data presentation (such as spreadsheets and basic graphics) obsolete in the future.
Already, a team of scientists at the Institute of Human Genetics of the Christian-Albrechts-University in Kiel, Germany, is using data visualisation to support a number of national and international projects looking at the epigenetic alterations related to several cancers, including malignant lymphoma, colorectal cancer, and hepatocellular carcinoma, as well as developmental disorders and other diseases.
‘Larger studies, especially those that include multiple samples that need to be analysed on comprehensive array platforms, have traditionally been very time-consuming, and have also required a considerable amount of computer power,’ says lead researcher Dr Ole Ammerpohl. ‘As humans, we are all used to interpreting 3D pictures in our environment, and so our brain is able to find structures in complex 3D figures very quickly. Therefore, it’s no wonder that a 3D presentation of complex mathematical or statistical coherences makes its interpretation much easier for us.’
Even though the exploration and analysis of large data sets can be challenging, the use of tools such as PCA and heat maps can provide a powerful way of identifying important structures and patterns very quickly, especially as visualisation typically provides the user with instant feedback, and with results that present themselves as they are being generated.
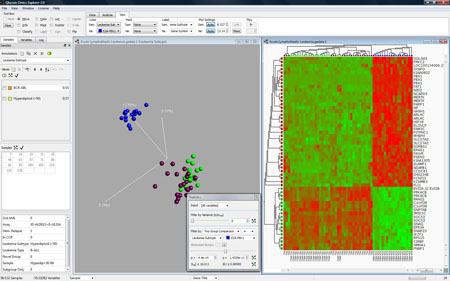
Data visualisation can show how some variables discriminate some samples (the blue group) from the rest
The evolution of Gene Expression Explorer
Qlucore started as a collaborative research project at Lund University, Sweden, supported by researchers at the Departments of Mathematics and Clinical Genetics, to address the vast amount of high-dimensional data generated with micro-array gene expression analysis. As a result, it was recognised that an interactive scientific software tool was needed to conceptualise the ideas evolving from the research collaboration.
Founded in early 2007, the company’s first product release was the Qlucore Gene Expression Explorer 1.0. The latest version of this software, Version1.1, represents a major step forward with the advanced statistics support. All user action is at most two mouse clicks away.
One of the key methods used by Gene Expression Explorer to visualise data is dynamic principal component analysis (PCA), a way of combining PCA with immediate user interaction. Dynamic PCA is PCA combined with instant user response, a combination that provides an optimal way for users to visualise and analyse a large dataset by presenting a comprehensive view of the data set at the same time.
With Qlucore Gene Expression Explorer, data is projected and plotted on the two-dimensional computer screen and then rotated manually or automatically and examined by the naked eye.